A while ago I was asked by a colleague the works on a different part of our product, what is bytecode instrumentation and how it is done. Bytecode instrumentation is a technique for changing the code of compiled Java applications[1], either before running them – on the disk, or “on the fly” as they are loaded into memory.
Why would you want to do something like that? The company I work for is an APM[2] vendor. An APM product will help you assess your application’s performance by showing you, for each business transaction, how it flows across application tiers, how much time it spends in each one, and hopefully, by providing some insight as for why it behaves the way it does[3]. So in essence, we make a “thin and wide” profiler for production time – thin because it has less features for each technology than a real profiler, and wide because it covers a broad set of technologies, and the interfaces between them. Bytecode instrumentation is one of the methods used to extract profiling information from applications, so naturally – we have much use for it.
We use it to add monitoring capabilities to applications without having to modify the monitored code manually. Code coverage tools may use this technique to inject tracing calls into the tested code, and then analyze the collected data in order to generate testing coverage reports. Frameworks may use instrumentation to implement some of their services.
It may seem like a wild idea at first – an application that modifies itself during runtime? Sounds like a script for a sci-fi movie! but it makes a lot of sense if you consider the way the JVM works.
Java is a dynamically loaded language. Every class is loaded lazily when needed using a component called a class loader. The class loader looks for the class code, reads it, and passes it to the JVM which links it with the rest of the code that is already loaded. This behavior makes Java very flexible – selection of concrete classes is deferred to the last possible moment, and the code itself can be brought from exotic places of all sorts[4].
Classes are stored on the disk in .class files, which are just a binary dumps of the memory structure that describes the class’s properties, and the code that it implements. The compiled code itself is kept in bytecode format – an intermediate language, which resembles assembly language. You can see the bytecode of a compiled class, as well as some of the other data stored in the compiled file, using the disassembly tool that comes with the JDK: javap (be sure to use the “-v” option in order to see the bytecode):

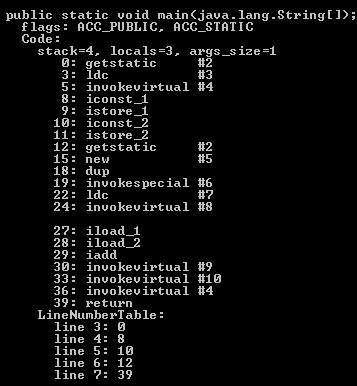
Normally, the class loader just reads the class file from wherever it is stored and passes it to the JVM as an array of bytes, but since it is just a structure in a well-defined and rather simple format, we can reason about the code and do some sophisticated things with it prior to that. In our case, the code is modified at that stage, right before the class is defined by the JVM.
There are several ways to “hook” this instrumentation mechanism into the JVM. You could implement your own special-purpose class loader and load parts of the code with it, you could instrument the JRE’s class loader on the disk, and have it call into your own code, and in Java 1.5 and up – there is a special instrumentation API that gives you access to the bytecode of every class right before it is defined. For the bytecode modification itself, you can use open source frameworks, like ASM and BCEL (which is somewhat outdated) that take care of some of the more annoying technical details involved in this process.
And this is bytecode instrumentation in a nutshell – seems magical at first, but really simple once you realize how it is done.
—
[1] And .Net applications, although the process differs from what I describe in this post
[2] Application Performance Management
[3] I like to call it pointing fingers scientifically
[4] Network locations, dubious coding sweatshops, whatever…

And for a different view on things, or a related subject (I’m not really sure which one), you should look at what is called AOP or “aspect oriented programing”.
Also, I feel obliged to note that programs that change their own code are rather… old, and more common that you might think. The thing is, why would a program change its own code? Or one program the code of another for that matter? Well, some profiling techniques work that way, some debuggers and so own. Most of the programs who practice in such things are, unfortunately, malicious (viruses, for example). In fact in the security world there are many measures (and counter measures) that deal with modifying code (or internal data – same thing really) on the fly.
Yes, bytecode instrumentation is one of the techniques you can use to implement AOP architecture – this is what we do.
Programs that modify their own code is not a new concept, but I find that it is quite interesting, and I was rather surprised to discover that many people who don’t work on this specific type of applications are often quite startled by the possibility to do that.
Personally, I like the fact that I understand how malicious software work. I don’t like the hacking and security worlds from various reasons*, but I find the techniques interesting. I really enjoy digging into other people’s work, and what I like the most about bytecode engineering is the way it changed how I think about software – it stopped being a rigid well defined structure, and became a soft piece of dough that can be shaped in endless ways.
* One is illegal, and just not very nice. It is also a closed subculture filled with ego – I don’t deal with this kind of environments very well. The other is just disgustingly hyped.
Really well written overview, thanks!